Intro — Shawn
This module will have a format that’s similar to modules 5 and 6. I’ll share my perspectives, and Loren will share his. Each will be labeled accordingly.
I’ll focus my attention on what and why. Loren will explain how.
Let me say, with all humility, that I can’t overstate how powerful this framework is once you understand how to use it. It’s a way to solve two of the most difficult problems we face when selling online — validating ideas and speed of execution.
Let’s dive in.
The Backstory — Shawn
It’s important to know where the idea for this testing framework originated to better apply the lessons to your own unique situation.
I and my team were working for a large, very sophisticated client that had several proven offers that we were hired to help promote. The client was working with another agency as well for implementation (my team’s role was advising on strategy and creating messaging).
That client had been taking a conventional, high-volume ‘curiosity and big promise’ approach to Facebook advertising. They had brute force on their side too with substantial ad budgets.
Loren’s first long copy ad substantially outperformed their previous ads, even with a variety of factors stacked against it. One of those factors was a mismatch between the free + shipping offer we had to work with and the direction we wanted to take the copy.
We had several ideas we wanted to test — however, we couldn’t ask the client to build us new funnels for each of those ideas without knowing which one might get traction.
That’s when the idea for this testing framework was born.
Before I explain how it works, let’s look at two conventional ways offers are created and tested. One example will be for a very small business, and the other will be for a very large business. They have a lot in common (which is where we’ll find our opportunity).
Example #1 — micro business. This is representative of all of us who have an idea that we want to make real. It could be a physical product, service, training, etc.
For purposes of this example, let’s assume it’s a training course delivered entirely online.
The process, in simple terms, looks something like this:
- Have an Idea for product, service, course, etc.
- Develop the course content and supporting material.
- Create the infrastructure to sell online (e.g., a simple funnel).
- Setup logistical support (domain, website email address, payment processor, learning management system, etc.).
- Create all of the necessary content to sell the offer (sales page, website copy, order form, etc.).
- Acquire traffic (email, organic, paid, affiliate, etc.).
- Measure results.
Even for a small business, there’s a LOT of work involved in creating all of the infrastructure to support selling the original product, service, or course idea.
Example #2 — established, large business. It’s easy to assume that larger companies create offers much faster than their small business counterparts. In my experience, that’s rarely true.
Larger companies have larger teams, but that does not mean faster implementation. In fact, often it means slower implementation. There are more layers of approval (including third-party legal reviews), larger teams (including outside agencies) which creates more interactions (increasing decision-making complexity), and often there are multiple, competing priorities.
Both examples are subject to two powerful forces. First, most of the offers either business creates will fail. We can safely assume the likelihood of failure is at least 80%.
Second, it’s impossible to know which offers will fail or succeed until they’ve been shown to an audience of prospects. There’s no top secret, behind the scenes method that pre-validates offers.
I can’t overstate the importance of that second observation. It’s easy to assume that the enormous direct-response powerhouses have methods to stack the deck substantially in their favor. They do not.
However, they do recognize that the offers that perform well will perform so well that the failures will be irrelevant. They only need a few blockbusters to propel their businesses forward because they can scale offers exponentially once they have something that performs. (That’s far less true for smaller businesses who need wins sooner and more often.)
Now we know the problem — what do we do about it?
To improve our odds of creating a successful offer that resonates with our intended audience, we need to reverse the order of the offer creation process.
Instead of creating the offer and then creating ad copy to drive traffic to it, we will test offer ideas with long copy Facebook ads, determine what the audience responds to as quickly as possible, and then build the full funnel on messaging that has been validated with an audience of potential buyers.
Re-read that paragraph a few times to make sure it really sinks it. It sounds obvious, at first, but it has enormous power once you begin to internalize the idea.
Let’s consider some examples with different levels of complexity.
The client mentioned above is an extreme example. We created a ‘plain vanilla’ landing page (so that wouldn’t affect the tests), and then five sets of ads (one theme for each set).
The base ad for each theme was approximately 600 words. Each base ad had five different leads (approximately 300 words each), and five different hooks (first two visible lines of the copy).
(Themes, leads, and hooks were explained in detail in Module 5, Part II.)
What we wanted to learn was which combinations of themes, leads, and hooks performed best before we invested the time, energy, and dollars to recreate the offer funnel with that specific messaging.
Instead of asking the client to trust us, we relied on data to tell us exactly which messaging got the most meaningful response from the audience.
Response can be defined broadly (Loren speaks to that in detail below). Ultimately, we cared most about purchasing behavior. However, that’s not a requirement. Engagement with the ad (comments, shares, clicks) or lead (volume and cost) can be effective assessments too.
I know what you’re thinking — there’s no way you’re going to create five ads with five leads and five hooks each. You don’t need to. That extreme example made sense for that specific client. More importantly, for you, the framework can be scaled down to projects of any size.
Let’s consider another example. This one will be for a micro-business just getting started. Rather than create all of the infrastructure to sell an unproven offer (hoping for the best and also knowing we’re likely to fail), we’re going to iterate our way to a validated idea with long copy Facebook ads.
After brainstorming ideas (following the Audience and Offer Masterclass, of course), we have decided that we want to create an offer for a $97, 1.5-hour course that shows people who are working from home how to setup their office and tech equipment for virtual meetings.
We think that our audience is most interested in:
- The specific technology they need (and how to set it up).
- Understanding software basics.
- How to setup fun backgrounds that communicate their personality.
However, we’re not really sure about any of that. They’re just guesses.
We also think it’s possible that our audience might be more interested in making virtual meetings more effective. Specifically:
- How to create an agenda if you’re running an online meeting.
- How to manage conversations to get more finished in less time.
- Alternatives to real-time virtual meetings that don’t require everyone to show up at the same time.
Which course should you create? Rather than guess, let your audience tell you. Create two ads that will be shown to the same audience. Don’t worry about leads and hooks — focus on the overall theme.
Theme #1 describes your first idea, and theme #2 describes your second idea. Both are shown to the same audience, and both link to a page where someone can sign up to be notified when the course is ready.
Then you run both ads simultaneously to see which generates the most interest (in this case, leads is probably the best initial measurement). Every time someone becomes a lead, send a personal email and ask a few questions. (If you want to do deep, ask if they’re willing to have a five-minute phone call with you.)
There are a few things to notice about this second approach.
First, there are enormous differences between the ads. The theme itself is completely different. This is not an A/B headline test — those happen (much) later. I want answers to big questions (will this offer resonate at all), not little questions (what’s the best headline to get interest in my offer).
Second, you get useful results quickly without spending a lot of money.
Third, you can act on those results immediately for additional insights.
Ask your prospects what they’re looking for. What do they hope to gain? What’s their biggest frustration? Then listen (closely) to their replies.
Is this a significant need or a minor annoyance? In what quantity and quality do they respond to your emails (i.e., what percentage reply, what percentage are willing to talk on the phone, and how much detail do they offer in their email replies and conversations)?
All of this data is important.
You may find that an audience is hyper-responsive, non-responsive, or somewhere in between.
You may find that what you thought would resonate doesn’t matter at all, and something you never thought about is vitally important.
The goal isn’t statistical significance. The goal is research. What gets engagement? What doesn’t?
It’s perfectly OK to say you’re thinking about creating something and want to know if someone is interested (a simple notification list works for this, a contact form on your website, or even an email address someone can click on).
I would not present your ads overtly as research, however. We want a cleaner signal — we want to know what an audience engages with initially (with the ad copy itself), and then by taking an action we think is potentially meaningful for future sales (e.g., becoming a lead).
This simple idea can scale up to whatever level of complexity makes sense for your business and your ad budget.
If you already have a proven offer, test 2-3 different themes to see which generates the most customers.
If you offer is completely dialed in, converting like clock work, test 4-5 different hooks to the same ad.
There is no limit to how you can use this idea, and you can adjust it to match your specific needs now and in the future.
Start small (A/B test with two ads) and focus your attention where it’s likely to create significant impact (themes, then leads, then hooks).
Don’t test the little stuff until you have identified the big stuff.
In my experience, the underlying idea and how you describe that idea are the two most powerful levels you can pull. Use this simple framework, with the details explained in Module 5, Part II, and develop your own tests to validate your ideas before you have committed more time, energy, and dollars than are absolutely necessary.
Then, when you see glimmers of hope, narrow your focus to what your audience has told you, with their behavior, they’re most interested in.
The faster you can do that the sooner you’ll know if your idea has potential to produce the results that you want. That is the Holy Grail of offer development — lower cost to deploy (measured in time, energy, and dollars), and exponentially faster execution when your data tells you it’s time to act.
Up next — Loren will explain (in detail) exactly what to measure, how to measure it, and why it matters.
Testing Methodology — Loren
A fellow Facebook marketer once referred to different testing approaches as “recipes.” That’s an accurate description. Just like every grandmother has her own recipe for chocolate chip cookies, Facebook marketers have their particular way they like to do things.
Here’s my recipe for testing with lower budgets.
I would use different procedures if I had a lot of testing budget to play with, but most businesses are not at that level. Plus, learning the reasoning involved in testing with lower ad spend puts us in a good position to pivot if when we’re profitable and it’s time to scale.
First, let’s understand the problems inherent in testing.
Testing is basically creating a science experiment. And just like we learned in high school science class, a well-designed experiment isolates the variable you want to test.
If we’re testing body copy, we want our copy to be the only difference between our ads. We’d obviously want the image and the headline to be the same for each variant we’re testing. We’d keep the landing page the same too.
But what about keeping the audience the same? We might be tempted to just put all the ads to be tested in one single ad set and call it a day. After all, we’ve now kept that variable identical for all ads, right?
Wrong.
We’ve got to remember that the Facebook algorithm is optimizing behind the scenes. As we learned in Module 5, an audience is just a large pool of people where the algorithm can roam.
What if one ad gets a lot of early activity while the algorithm is roaming through a bad part of the audience pool, while another ad happens to get shown later when the algorithm has learned and is now roaming through a high-performing area of the pool? In that case one body copy variant might appear to do very well when it was really just differences in the audience.
For a well-designed science experiment, we would want truly random samples of our audience to see our ad. But due to the algorithm’s efforts, that is not possible. This must be taken into account when we test. It is the reality on which our testing is built.
It is also crucial for us to understand our goal with testing. This sounds obvious but it’s worth stating again and again. If we are testing body copy, we want to find the winning copy. We may not get purchases or leads, and that’s fine.
We may also construct our testing campaigns in a way that is very different from a campaign that we’re going to scale. Again, that’s fine. Testing is our goal, so our campaigns will look different.
Finally, we need to understand the limits of the data that we are getting. In order to have statistically ironclad test results, we would need to spend an enormous amount of money for each single ad variant.
We may need to run around 100 conversions for each variant in order to have statistically significant data. If the average CPA for a purchase was $30, that would be $3,000 in testing budget for every single ad variant. If you want to test 5 copy variants and 5 image variants, that would be 125 total ad variants — so around $375,000 in ad spend!
That’s simply not feasible for most businesses. And even if a business could afford it, it’s not desirable or necessary.
Instead, what we will be doing is looking at secondary metrics (such as clicks) and making judgment calls. As much as we love data and want to rely on it heavily in our testing, we will be making decisions with limited data in order to be efficient with ad spend.
Don’t stress too much about this. Understand that testing just gives us a snapshot peek into how an ad will eventually perform. Even though it may not be bet-your-life-on-it accurate, the results from testing will probably hold up. We must be content with “probably” if we’re going to conserve ad spend.
With that foundation outlined, here is my testing framework. Perhaps the foundational principles will make more sense when you see them fleshed out in the practical testing steps.
There are many elements we could test: images, headlines, audiences, placements, copy, and more. Even within the copy, there is much to test: the intro, the call to action, the copy length, etc.
In pursuit of the 20% of activities that drive 80% of results, the two elements most worth testing are the copy intros and images. Yes, test audiences, test body copy, test everything. But copy intros and images will be your most valuable tests.
Copy Intro Testing Framework — Loren
No. 1 — Optimize for the eventual desired event.
If the test winners are going to be run in a campaign optimized for purchases, then optimize for purchases in the test campaign. This is one area where we want the test conditions to be the same as the conditions we will use in campaigns we’ll scale.
When optimized for purchase, the algorithm will roam around and show the test ads to those who it thinks will purchase. Those are the same type of people who will see the ads eventually in your scaling campaigns, so those are the type of people you want to evaluate your creative in your test campaigns.
If we are optimizing instead for landing page views or add to carts in our tests, then the algorithm would show the ad to the types of people who will take those actions. We may think all of these groups would all be related, but that is wrong. You will be surprised how different they are.
No. 2 — Put all variants into the same ad set.
When all the ads are in the same ad set, the algorithm learning at the ad set (audience) level is kept as uniform as we can make it. Some testing recipes call for multiple ad sets with one ad in each ad set. That’s an acceptable alternative, but I prefer to have all ads in the same ad set learning environment. With multiple ad sets, what if the algorithm just starts off lucky in one ad set but starts off in a bad part of the audience pool for another ad set? The variability in audience quality due to the algorithm is amplified when we have multiple ad sets.
No. 3 — Choose an audience you know works well.
Run with an audience that has historically performed well. Something like a 1% lookalike of customers is also a good choice. Or If you don’t have any data to build a lookalike audience, then do the best you can with interest targeting.
You may wish to spread your risk and try out two or more ad sets of interest targeting (or also test out a broad audience) if you’re starting from scratch and are unsure of what audience will work. However, still put each ad variant in each ad set.
No. 4 — Exclude warm audiences.
Make a custom audience of anyone who has engaged with your Facebook page, a custom audience of anyone who has visited your website, and any other audiences of people who have had interactions with your business. Exclude those custom audiences from your tests.
To explain why I recommend this, let me back up and explain a little more about how the algorithm approaches cold and warm audiences.
Let’s say we are selling mountain bike supplies and are using “mountain biking” as an interest we are targeting. In the U.S. that’s an audience pool of 10 million people.
Let’s also say that we have a somewhat warm audience of 1,000 people who have interacted with our Facebook page or website recently.
Many of those 1,000 people (if not all of them) would be part of that 10-million-person audience pool. So unless we specifically exclude them, they may be served ads when we target “mountain biking.”
That might not seem like a big deal. After all, that warm audience of 1,000 people is 0.01% of the total pool. But remember, the algorithm is not showing ads to random members of that audience. It is roaming around in the pool using all of its data to find those who are most likely to engage with the ad and become a purchaser.
And who do you think the algorithm calculates may be very likely to engage with the ad and purchase? The people who have already engaged with your page or visited your website recently.
What this means is that, even though your warm traffic audience is 0.01% of the audience pool, they will receive a disproportionately large percentage of the impressions. This is almost guaranteed.
In some cases, this can be a massive difference. Facebook may hammer your warm audience with your ads multiple times a day, day after day. Meanwhile, 99.5% of that 10-million-person audience pool hasn’t seen the ad once.
This isn’t Facebook doing anything dirty. In fact, the algorithm is actually doing a great job of trying to deliver what you’ve asked for. You’ve given the algorithm an audience pool of 10 million, and it’s trying to give you purchasers from that pool.
It is our responsibility to understand this quirk of the algorithm and to construct our test campaigns around it. If we don’t exclude our warm audiences, Facebook will inevitably target them heavily in our test campaigns.
Many testing strategies don’t worry about these warm traffic audiences. Their logic is that these warm audiences may eventually be seeing your ad, so you might as well test the ad that way. They also point out that we would benefit from knowing what works or doesn’t work with our warm audience.
I can see their point. However, I don’t want one ad getting shown to a large number of people who already like your brand, while another ad just happened to be shown to no one familiar with your business. In that case, it might appear that one ad did well and one ad did poorly. But it’s not the creative that is the cause, it’s the uneven audience distribution.
To isolate that variable, I exclude warm audiences.
No. 5 — Use the news feeds for placements.
Don’t use automatic placements for your test ads. I would recommend just using the Facebook news feed. If your business has a heavy presence on Instagram, you could also add the Instagram feed (or even better, run a separate test only to Instagram).
This is to eliminate any impact the variability in feed placement could have. I have seen tests where one ad variant was shown heavily on the right column placement, and it performed very poorly. Digging deeper, it was not the ad creative that was to blame but the placement. By selecting the feeds, this is just one more variable we keep consistent.
No. 6 — Create an ad for each intro copy variant you want to test.
I’ve tested as few as three and as many as twelve variants. One strength of this testing framework is that it is budget efficient, so testing more variants is feasible economically.
Some testing recipes call for using dynamic creative instead of creating individual ads. That approach could work, but later I will explain the downside to dynamic creative. I should also add you can only have five body copy variants with dynamic creative, so individual ads are the way to go if you want to test more variants.
No. 7 — Keep the headline and other creative elements the same for each ad variant.
Choose an image that works but is conservative. We don’t want polarized reactions to an image to overshadow the copy we’re testing. Don’t use an image with text in it as that detracts from the copy you are testing. We may eventually test wild-looking images or text-based images, but we want the copy to shine for the copy testing.
No. 8 — Calculate your budget and goal for impressions.
We want each ad variant to get a certain number of impressions. That exact number is dependent upon your budget and your tolerance for statistical uncertainty. The more impressions, the more data we will get and the more reliable our test data will be.
I would recommend an absolute minimum of 500 impressions per ad variant. Normally I am looking for anywhere from 1,000 to 3,000 total impressions per ad variant. 1,500 is what I normally choose.
We can set our game plan with some calculations. Take a look at the recent CPM (cost per 1,000 impressions) you have been getting for campaigns with the same optimizing event. If you don’t have any data, you can estimate based on account history or just prepare for around $30-$40 CPM. (That’s a very broad average across multiple industries that could be wildly different from yours, but it’s at least a starting place.) Let’s say your average CPM for purchase campaigns was $25.
Now we know approximately how much we will spend per 1,000 impressions. The next step is to do some simple math to determine the cost for each ad variant.
If we have five ad variants and we want to receive 1,000 impressions for each ad variant, that’s 5,000 impressions total. At $25 CPM, that would cost about $125.
If you’re comfortable spending more to receive more data, you could choose $250 for 2,000 impressions on each of the five ad variants. If you want to spend less, you could test fewer variants or aim for a lower number of impressions per ad. (Again, I would never advise fewer than 500 impressions and would personally recommend at least 1,000 impressions per ad.) If I had to lower the cost in this example, I would opt for three variants at 1,000 impressions each for a cost of approximately $75.
The next step would be to calculate your daily ad spend.
I would want the ads running ideally over the course of multiple days, normally about three or four. You may want to take weekends into account and have your test schedule spread out over weekdays and weekends.
So if our test budget was $250 spread out over three or four days, we could set a daily budget of anywhere from $60 to $90.
No. 9 — Start running the ads.
For any new ads–for testing, scaling, prospecting, retargeting–I always recommend scheduling ads to start in the very early morning.
No. 10A — (Easy Version) Set up automated rules to stop ads.
It’s important that we now turn off the ads after they receive their goal number of impressions.
You’ll notice that Facebook will tend to favor one or two ads and send most of the impressions to those ads. (I think this is a calculated move on Facebook’s part to sacrifice statistical accuracy for quick results. That’s what the average mom-and-pop advertiser wants.)
If we just let Facebook distribute impressions, we may end up with one ad at 5000 impressions while another ad is at 500. With Facebook in control of where our impressions go, it would take a lot of budget to get every ad to our minimum number of impressions.
So we want to turn off ads when they reach our impression goal. That way, Facebook is forced to show the other ads. Turning off the ads one by one will make sure that each ad gets the minimum number of impressions we desire. And when we turn off ads immediately when they reach our goal number of impressions, we don’t have any wasted ad spend.
This is the main reason why I’m not a fan of using dynamic creative for testing. We are unable to turn off individual ad variants, and thus we surrender control of where our impressions go.
Theoretically we could monitor the ads very closely and manually turn off each ad once it reaches our goal number of impressions. But that is wildly impractical. A better alternative is to use automated rules. This way you don’t have to babysit the ads. You can set it and forget it.
I do this by creating an automated rule to turn off all ads with lifetime impressions greater than your goal impressions AND with the ad name containing some testing term that you would never accidentally use in any other ad.
Here’s a screenshot of how I’d do it. This is the setup for a rule to turn ads off after 1500 impressions if the ad contained [TEST1500] in its name.
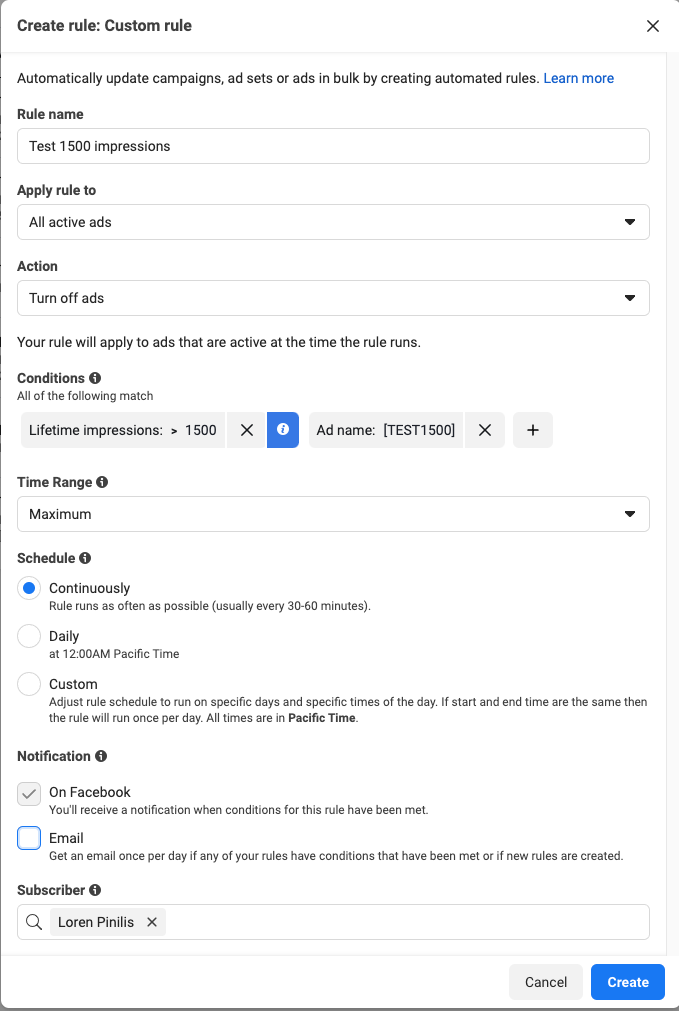
Just make sure you put [TEST1500] in the ad name, turn on traffic, and come back in a few days to bask in the glorious data.
No. 10B — (More Involved but Awesome Version) Set up automated rules to run mini-rounds of testing.
This takes a little extra elbow grease, but I believe it helps us achieve more accurate results with lower impression numbers. It may be overkill if you’re spending $500/day testing. But this is a good way of going the extra mile to maximize limited testing budgets.
We will use the exact same process as the easy version (Step 10A) with only a few extra steps. Instead of running one round of testing to our goal number of impressions, we could split that up into mini-rounds.
Allow me to explain with an example.
Let’s say our impression goal is 1500 impressions. We have an automated rule setup to turn off the ads when they reach 1500 impressions as long as the ad contains [TEST1500] in the ad name.
But instead of running straight to 1500 impressions, let’s set up an additional automated rule to turn off all ads at 750 impressions if the ad name contains [TEST750].
Now we put [TEST750] in the ad names and run them as before. They will turn off at 750 impressions. Wait until every ad has reached our 750 impression threshold and turned off. The next step is then to change the ad name so it contains [TEST1500] instead, and then we restart all the ads again. They will run until they receive 1500 impressions and then turn off.
Essentially we’ve just split up our testing into two rounds instead of one.
So the obvious question is why are we doing this?
Remember that Facebook likes to pick winning ads very quickly, trading accuracy for quick results. There is also algorithm learning going on so that the audience seeing the later ads may be higher quality than the audience seeing the early ads.
When the ads stop and restart (like we did at 750 impressions in the example), the algorithm has a slight reset and starts learning again. This would never be advisable when we wanted to scale and optimize, but shaking up the algorithm during testing helps us even out audience distribution.
We also are potentially evening out other variables like the day of the week or the time of day. (With two rounds, we wouldn’t have all impressions for one ad variant come on a Saturday, for example.)
That gives us a little more reliable data for a small number of impressions.
No. 11 — Analyze results.
Once all the ads have received our goal number of impressions, now we can analyze the test results.
As mentioned earlier, we won’t be able to use purchases or leads as our primary metric for evaluating ads (except in the rarest of circumstances). We will be using secondary metrics.
Will these secondary metrics give us a window into the ads that will do the best job of getting actual purchases or leads? The best we can say is they probably will. That is just the nature of testing.
There are four main metrics I consider when evaluating test results.
The least important of the four is purchases (or leads). Unless you’ve got dozens and dozens of purchases with your test ads, there’s not enough data to make this a reliable indicator. It’s nice to see and look at, but rarely do I give it much credence. It’s more just to confirm, if possible, what I’m seeing with the other metrics.
The other three metrics are centered around clicks. If we are doing a good job of prequalifying with our ad creative, click activity is a highly relevant measurement of the ability of an ad to drive results.
In order of importance, I evaluate:
- CPC
- CPC(all)
- Ratio of CTR(all) to CTR
- Conversions
I am looking for the lowest CPC and the lowest CPC(all).
For the ratio of CTR(all) to CTR, I’m looking for around two to five. But that’s not set in stone. I mainly like to see if there is any weird deviation here as explained in the Reporting Module.
If this deviation is happening on only one test ad, then the problem is the intro copy for that variant. If this deviation was happening on every ad, I may suspect the image (because the image is the same in all our test ads).
Using these four metrics, I like to pick out a few winners to move forward with. You may notice that the three ads with the lowest CPC are also in the top five for the lowest CPC(all). The ratio of CTR(all) to CTR looks good. Maybe one or two of them also did well generating conversions. In that case, you’ve got your three winners.
How many winners to choose may also depend on how closely matched the test ads are. If three out of ten copy intro variants are head and shoulders above the rest, run all three of them in our scaling campaigns. If just one variant is a superstar, run it alone and prepare more ads to test. Or pick five. Or pick two. You have information now on what intros work, so do what you want with that info.
No. 12 — Optional: Run additional rounds
Because we have run these test ads as individual ads, we are in complete control if we want to give any ads some additional impressions.
If we are worried about having too little data, run the ads for another few hundred impressions to give us a clearer picture. If we want some more information about a particular ad, we could run it alone for more impressions. If we have two or three ads that are closely ranked and we want to pick a definite winner, run just those ads for more impressions.
This recipe takes more work on our part. But the result is greater efficiency in our ad spend budget.
Testing other elements:
Remember, the two elements most worth testing are the copy intros and the images.
For image testing, I would use the exact same framework. I would just pay closer attention to the CPC(all) and the ratio between CTR(all) and CTR. Those two metrics are heavily impacted by the image.
If you choose to test headlines, the same procedure would also work well.
If you choose to test the remainder of the body copy, I would use the same framework again. Although if I were very curious about the body copy’s impact on conversions and not just clicks, I might run the tests for many more impressions if budget allowed.
Testing audiences is where the framework differs significantly.
First, our goal is different. With ad creative testing, we were looking for our winners. We wanted to find the best performers to be displayed to our audiences.
With audiences, we aren’t looking for winners. We are just looking for the audiences that work. Every single audience might meet the threshold of performance.
To start the testing, I would first choose ads you know will work. For lower budgets, I would begin with something like the two winning copy variants and two winning image variants, giving me four ads total.
Create an ad set for each audience you want to test, publishing those four ads inside each ad set. Set a daily budget for each ad set rather than going for campaign budget optimization.
Then just run traffic to the audiences as your budget allows. Here, we want to let the algorithm optimize as much as possible so we can see the audience’s potential. Rather than starting and stopping ads with automated rules as before, we let the algorithm go at it.
Ideally each audience has enough daily budget to get around ten conversions per day, and ideally we are running this test for at least three days if not a week. This gives the algorithm enough data to optimize, painting a clearer picture of an audience’s true performance.
This will likely be a higher ad spend and many more impressions than we ran for our ad creative testing, but that’s what audience testing requires.
Many concessions may need to be made depending on our budget and how many audiences we want to test. We may need to reduce the number of tested audiences in order to find that sweet spot of daily conversions. We may be unable to get anywhere close to that amount of daily conversions. Do the best you can in your circumstances.
After a few days, we can begin to analyze our audiences. But don’t turn the ad sets off yet. Leave the audiences running while we take a look at the data.
When analyzing audience data, I will slightly look at CPC and CPC(all). But with audiences, I am primarily interested in conversions and the cost per conversion.
You can view the data for each particular day, and you may notice that an audience’s daily results vary wildly from one day to the next. This is particularly true in the first day or two as the algorithm is learning.
With that in mind, I will often ignore the data on the first day of testing if it just seems too erratic. I may do the same for the data on the second day. (So I may run traffic to an ad set for seven days, ignoring the first two and analyzing the combined results from the last five days.)
We’ve given the audiences a few days to perform, so they’ve “had their chance.” If an audience was not able to get a CPA we’re happy with, then we turn the ad set off. If we’re unsure of its performance and want more data, leave it running for as long as you can tolerate a bad CPA.
If an audience is meeting your CPA standards, let it run for as long as you wish.
Congratulations! All your hard work with testing has paid off. You now have profitable Facebook ads. Now you can use these proven ads and audiences in other campaigns as you scale up and continue to optimize.
Summary — Shawn
This bonus module is dense. There’s no way around it. Loren spends all day every day doing this work and he is very good at it. What you’ve just read is a look inside the mind of someone who exemplifies the distinction between knowing how and being able.
Knowing how is conceptual. Being able is action-oriented. The difference between the two seems subtle but it’s not.
The way to know how to do this work is to take a deep breath and do it. Re-read this module 2-3 times. Write down your questions (and bring those to the next Q&A call) or ask in the comments.
Then, do the work. Test your first idea. Keep it simple. Get something to move the needle once and you’ll understand, viscerally, how powerful this framework can be. It will become your secret weapon for testing ideas quickly, and validating ideas that show signs of life.
This module is your secret weapon. Use it wisely.
— Shawn & Loren
NEXT: TTE Q&A Call #3, Module 5